
intro: 나의 첫 번째 프로젝트
2024년도가 2주일도 채 남지 않은 시점인 2024년 12월 19일부터 시작된 무한도전 사진 박물관 프로젝트에 대한 기록을 남겨보고자 한다. 개발 블로그 취지에 맞는 글을 처음 써보는 것이라 어떻게 시작하고 마무리해야 할지 고민이 많고 부족한 점이 있겠지만, 내가 어떤 과정을 통해 무엇을 만들고자 했는지, 적용한 기술과 트러블슈팅, 그리고 개발 과정 속의 고민들을 녹여내고자 한다.
프로젝트 시작 계기 및 주제와 방향성
사실 프로젝트를 시작하게 된 계기는 정말 간단하다. HTML/CSS 강의를 듣던 중 Flex 레이아웃과 Grid 레이아웃에 대한 연습을 하고 싶었다. React 같은 프레임워크를 사용하는 대신, index.html 파일을 만들고 style.css 파일로 간단히 레이아웃을 잡아보며 GitHub를 이용해 정적 페이지 호스팅을 해보자는 아이디어가 이번 프로젝트의 초안이 되었다.
학부생 시절, 캡스톤 디자인이나 팀 프로젝트를 진행할 때 가장 어려웠던 과정은 바로 ‘무엇’을 만들 것인가?였다. 개발을 통해 어떤 서비스를 제공할지 설계하고 기획하는 것이 굉장히 힘들었다. 그래서 이번 프로젝트는 단순히 페이지를 만들어보는 것이 목표였기 때문에 내가 좋아하는 것을 주제로 하기로 했다.
그렇다면 내가 좋아하는 게 무엇일까? 곰곰이 생각해보니, 나는 무한도전 짤을 자주 찾아보고 사용하며, 레전드 영상을 지금도 자주 시청한다. 무한도전이라는 프로그램 자체를 정말 좋아했고, 지금도 밥을 먹을 때나 기분이 좋을 때, 혹은 안 좋을 때에도 쿠팡플레이로 재방송을 챙겨볼 정도로 좋아한다. 이런 애정을 바탕으로 무한도전을 중심으로 한 서비스를 만들어 보면 어떨까 하는 생각이 들었다.
그리하여 무한도전에서 나온 사진들 중, 보기만 해도 웃음이 나는 사진들을 사용자들에게 제공해 보자!라는 아이디어를 가지고 나의 첫 번째 프로젝트는 시작되었다.
초기 페이지 구성
페이지의 레이아웃은 큰 틀은 grid 레이아웃으로 잡았다. 아무래도 내부적으로는 flex 레이아웃을 이용해서 배치를 어떻게할지 고민하는게 더 낫다고 생각했고 두가지 레이아웃을 혼합해서 사용해보고 공부한 내용을 적용해 보고 싶었기에 깊은 고민은 하지않고 바로 실행으로 옮겼다. 이 글을 쓰는 시점이 이미 어느정도 개발이 진행되고 있는 과정속에서 늦은 기록이 진행되고 있기에 완전 초창기의 사진은 없으나 다행히 초창기에서 조금더? 지난 시점의 사진은 남겨 둘 수 있을 것 같다.
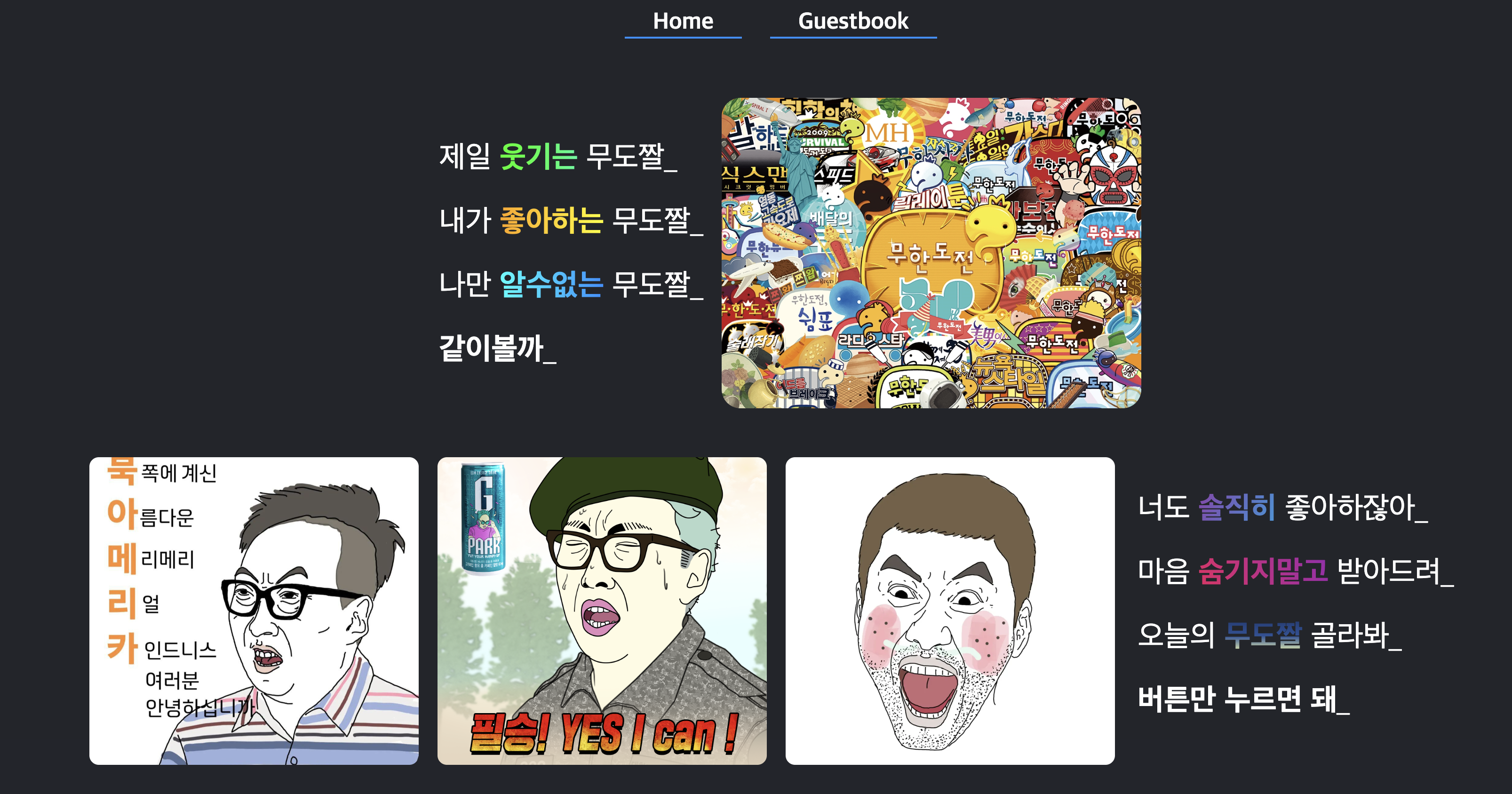
위 페이지에 대해서 간단히 소개를 하자면, 페이지 하단의 버튼 당겨요! 버튼을 누르면 프로젝트 폴더안에 저장해두었던 움짤 사진들이 랜덤으로 화면상에서 돌아가면서 그중에 하나가 화면상에 보여지게 되고 페이지에 폭죽이 터진다. 초기의 목표가 사용자에게 무한도전의 웃긴 사진을 보여주어 웃음을 주는게 목표중에 하나였기에 js까지 동원하여 기능을 구현하였고 레이아웃 연습도 했고 기능적으로도 나쁘지 않다고 생각했기에 이대로 마무리 하고자 하였었다.
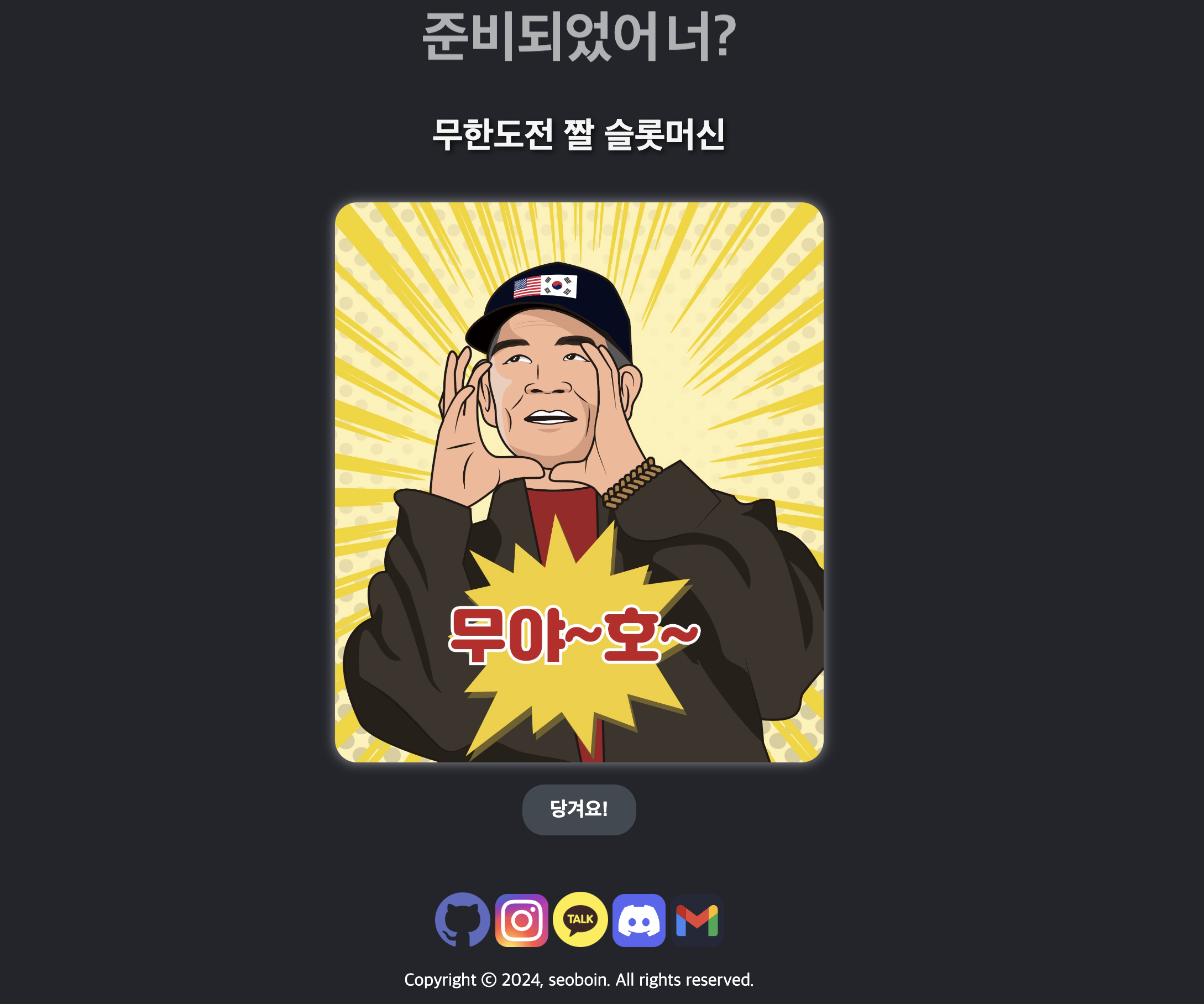
페이지 확장
위 이미지를 보면 탭이 두가지가 있다. 기존에 설명하였던 홈 화면과, 방명록 탭이 존재하는데 페이지를 다만들고 주변 친구들 혹은 가족들에게 보여주고 반응이 어떨지 궁금했고 개인적인 생각 혹은 피드백을 받으면 좋을거 같다는 생각이 들었다. 그러나 정적 페이지 이기에 페이지가 새롭게 빌드돠거나 새로고침만 해도 데이터가 날라가기에, 영구적으로 데이터를 저장할 공간이 필요하였다. 하지만 그렇다고 해서 AWS의 RDS를 쓰기에는 비용적으로도 문제가 있다고 생각했고 애초에 이 시점에서는 ‘많은 사용자가 이용하는 서비스를 만들자’ 라는 생각을 하지도 않았었기 때문에 무료로 사용가능하면서 클라우드 서비스로 제공되는게 있으면서 간단하게 사용할수도 있고 차후에 다른 DB로 변경하게 되더라도 문제가 없을만한 서비스를 찾아보게 되었고 결국에는 FireBase의 Realtime Database를 선택하게 되었다.
FireBase의 Realtime Database가 뭔데?
Firebase의 Realtime Database는 Firebase에서 제공하는 클라우드 기반의 NoSQL 데이터베이스로, 실시간 데이터 동기화를 지원하는 서비스이다. 별도의 EC2 환경에 설치할 필요 없이 클라우드 서비스를 통해 손쉽게 이용할 수 있어 매우 편리하다. 설치 과정이 필요 없다는 점이 큰 장점이며, 데이터베이스 생성과 활용도 간단하여 간단한 프로젝트에서 NoSQL을 도입하려는 경우 Firebase를 적극 추천한다. 실시간으로 데이터가 동기화된다는 장점이 있다고 하는데, 가끔 데이터 업데이트가 될때 FireBase 콘솔에서 업데이트 된 항목이 주황색 배경으로 빛나서, 변경된 항목이 무엇인지 알 수 있는것 같기는 하다.
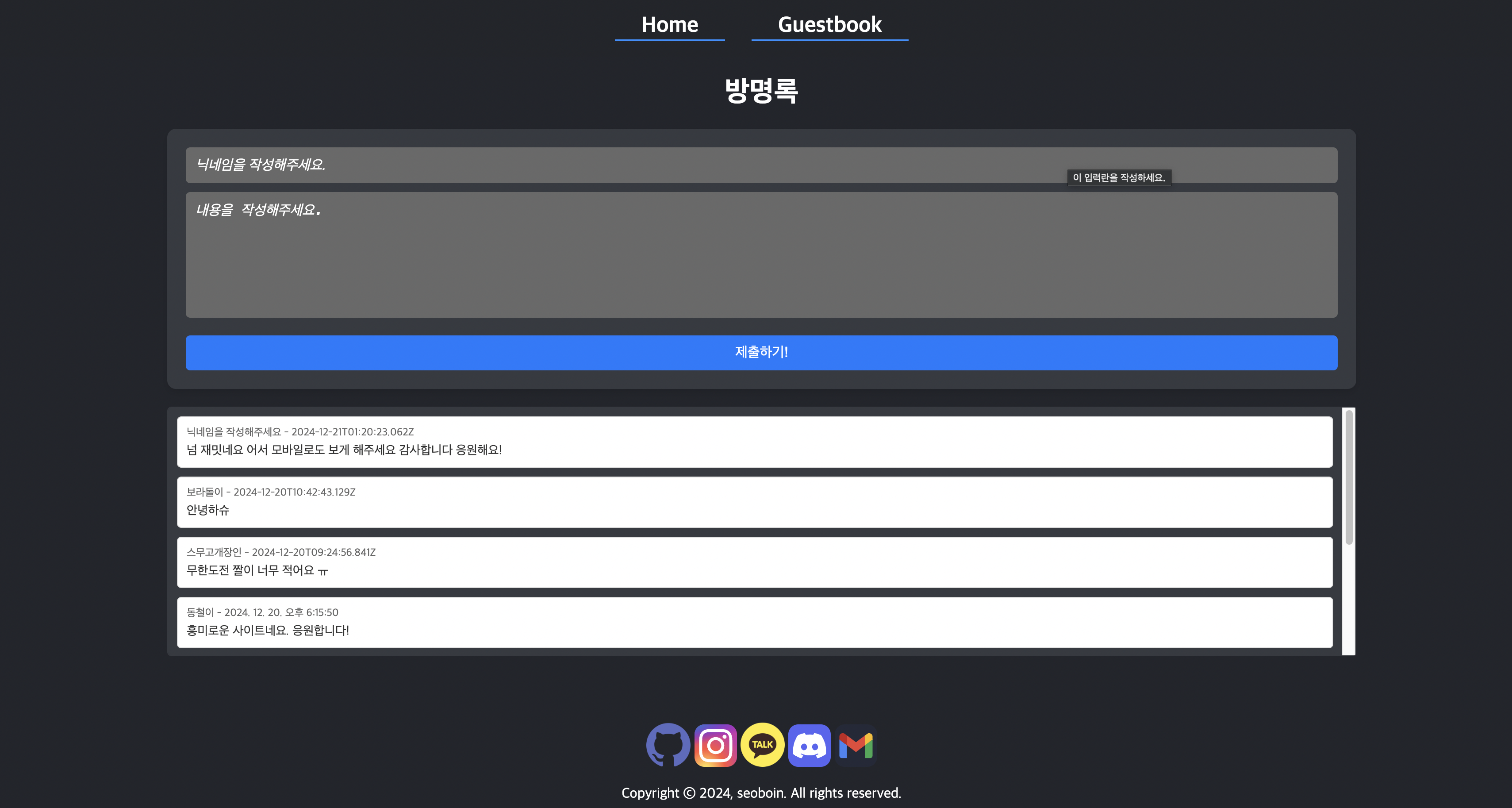
방명록 페이지 개발
위 DB가 연동이 되고 나니, 방명록 기능 개발은 일사천리였다. 프론트 방명록 페이지에서 입력받은 값을 FireBase에 저장하고 해당 값을 화면상에 보여주기만 하면되는거니까 매우 쉽게 다음 이미지와 같이 방명록 페이지 개발이 완료되었다.
서버 개발의 시초
이 시점에서 사실 레이아웃 연습도 해볼만큼 해봤고, 방명록 페이지까지 만들어서 간단하게 주변 사람들 반응도 볼수 있었고 재미도 있었다. 근데 어쩌다보니 욕심이 나는게 더 다양한 이미지를 보여주면 어떨까? 사람들이 더 많은 재밌는 짤을 내 사이트에서 쉽게 찾는다면? 복사 및 다운로드를 쉽게 할 수 있다면 좋지 않을까? 라는 생각이 들었다. 그렇게 생각을 하다보니까 이미지를 크롤링 하는 서버가 필요하겠다! 싶었고, AWS의 EC2를 이용해야겠다는 생각이 들었다.
Selenium? Google Custom Search API?
그렇다면 크롤링을 하는 방법 부터 정해야 하는데 가장 유명한 방법은 파이썬에서도 자주 사용하는 Selenium 이었다. 근데 크롤링을 하려면 대상 페이지에 대한 분석이 필수이며 해당 DOM 트리의 구조를 잘 알아야 쉽게 크롤링을 할 수 있는데 구글을 상대로 페이지 분석을 해서 합법적인 방법으로 크롤링 할 수 있을까? 라는 생각이 들었다. 이전 학부생 시절 학습용으로 하던 구글 이미지 크롤링의 경험상 유지보수도 복잡하고 힘들었던 기억이 나기도하고, 네이버 이미지 크롤링을 하다가 사이트 차단을 일시적으로 Block을 먹어본적도 있었기에 뭔가 Selenium은 손이 가지 않는 방법으로 판단이 되었다. 그렇다면 좀 더 합법적이면서 확실하게 크롤링을 할 수 있는 방법이 없을까? 해서 찾아보니, 구글에서는 다음과 같은 API를 제공했다.
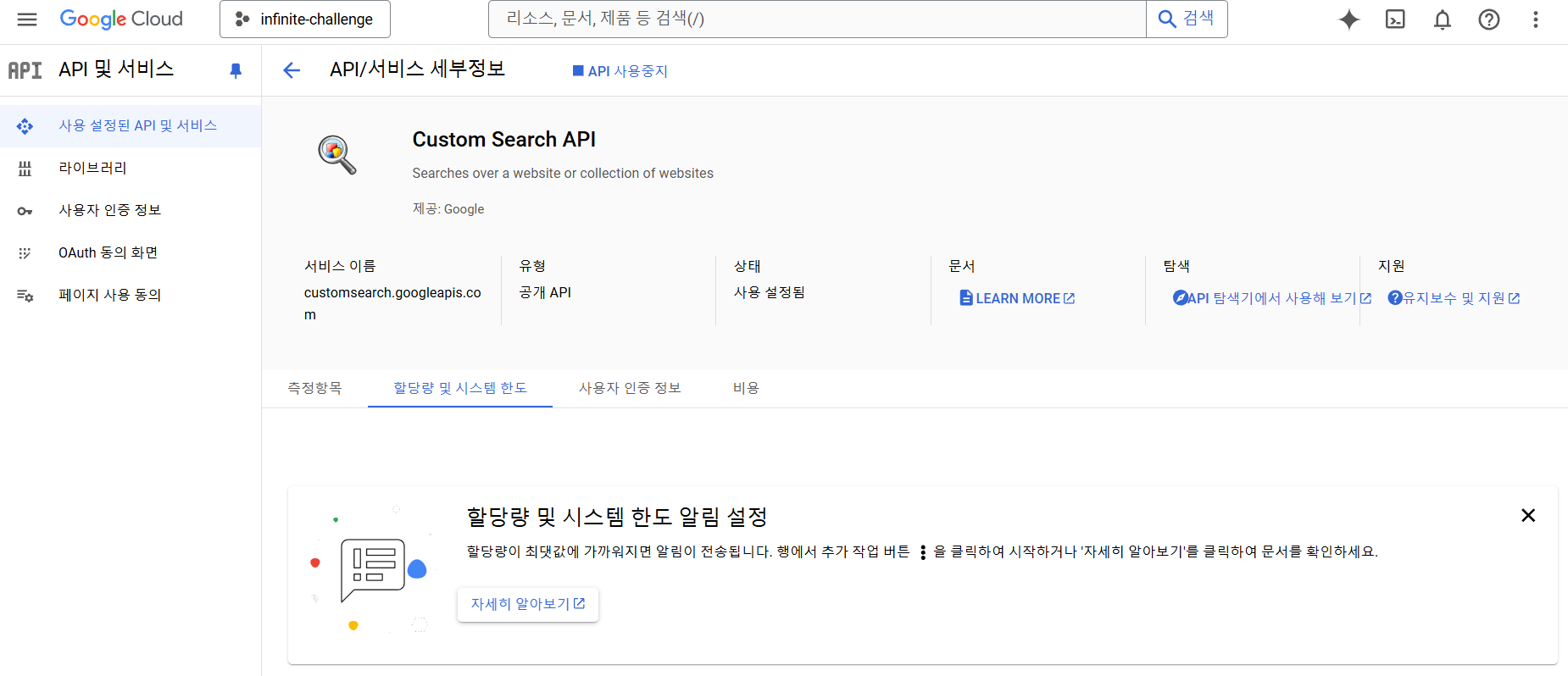
이전에 Google Vision API를 사용해본 경험도 있고 Google의 Open API에 대한 인식이 굉장히 좋았기에 바로 적용해 보고자 하였다. 결과는? 당연히 굉장히 만족스러웠다. 리턴값도 굉장히 다양하게 반환되며 이전페이지와 다음페이지의 여부에 대한 정보도 반환되어 부가적으로 쓸모있는 정보들도 반환받을 수 있으며 당연히 내가 원하는 이미지의 주소값도 반환 받을 수 있었다.
// return 값 일부 중 발췌
{
"kind": "customsearch#search",
"url": {
"type": "application/json",
"template": "https://www.googleapis.com/customsearch/v1?q={searchTerms}&num={count?}&start={startIndex?}&lr={language?}&safe={safe?}&cx={cx?}&sort={sort?}&filter={filter?}&gl={gl?}&cr={cr?}&googlehost={googleHost?}&c2coff={disableCnTwTranslation?}&hq={hq?}&hl={hl?}&siteSearch={siteSearch?}&siteSearchFilter={siteSearchFilter?}&exactTerms={exactTerms?}&excludeTerms={excludeTerms?}&linkSite={linkSite?}&orTerms={orTerms?}&dateRestrict={dateRestrict?}&lowRange={lowRange?}&highRange={highRange?}&searchType={searchType}&fileType={fileType?}&rights={rights?}&imgSize={imgSize?}&imgType={imgType?}&imgColorType={imgColorType?}&imgDominantColor={imgDominantColor?}&alt=json"
},
"queries": {
"request": [
{
"title": "Google Custom Search - 무한도전",
"totalResults": "158000000",
"searchTerms": "무한도전",
"count": 10,
"startIndex": 1,
"inputEncoding": "utf8",
"outputEncoding": "utf8",
"safe": "off",
"cx": "",
"searchType": "image"
}
],
"nextPage": [
{
"title": "Google Custom Search - 무한도전",
"totalResults": "158000000",
"searchTerms": "무한도전",
"count": 10,
"startIndex": 11,
"inputEncoding": "utf8",
"outputEncoding": "utf8",
"safe": "off",
"cx": "",
"searchType": "image"
}
]
},
"context": {
"title": " infinite challenge-search-engine"
},
"searchInformation": {
"searchTime": 0.294487,
"formattedSearchTime": "0.29",
"totalResults": "158000000",
"formattedTotalResults": "158,000,000"
},
"items": [
{
"kind": "customsearch#result",
"title": "무한도전] (믿고 보는 몸개그 BEST) 유재석이 찐으로 웃으면 뭐다 ...",
"htmlTitle": "<b>무한도전</b>] (믿고 보는 몸개그 BEST) 유재석이 찐으로 웃으면 뭐다 ...",
"link": "https://i.ytimg.com/vi/CCTDvm8Va78/hq720.jpg?sqp=-oaymwEhCK4FEIIDSFryq4qpAxMIARUAAAAAGAElAADIQj0AgKJD&rs=AOn4CLAxeGqCiiAsXoEgd5yJ0CaQOwSFSw",
"displayLink": "m.youtube.com",
"snippet": "무한도전] (믿고 보는 몸개그 BEST) 유재석이 찐으로 웃으면 뭐다 ...",
"htmlSnippet": "<b>무한도전</b>] (믿고 보는 몸개그 BEST) 유재석이 찐으로 웃으면 뭐다 ...",
"mime": "image/jpeg",
"fileFormat": "image/jpeg",
"image": {
"contextLink": "https://m.youtube.com/watch?v=CCTDvm8Va78&t=77s",
"height": 386,
"width": 686,
"byteSize": 70317,
"thumbnailLink": "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTtN7UlkqwnJ8oTC3Cs2NYNnrqETJB4tWO7OkKcP2-_tnyEkYDYczRnG8s&s",
"thumbnailHeight": 78,
"thumbnailWidth": 139
}
},
{
"kind": "customsearch#result",
"title": "무한도전 - 나무위키",
"htmlTitle": "<b>무한도전</b> - 나무위키",
"link": "http://i.namu.wiki/i/MDO4mGHS56yu2vBufeG8r05-cIY_aUfNya_edTqEKbjfhn43p4odUEq0y9zuKCOj5Jk4r67VmQACE2BSkWjxbg.svg",
"displayLink": "namu.wiki",
"snippet": "무한도전 - 나무위키",
"htmlSnippet": "<b>무한도전</b> - 나무위키",
"mime": "image/svg+xml",
"fileFormat": "image/svg+xml",
"image": {
"contextLink": "https://namu.wiki/w/%EB%AC%B4%ED%95%9C%EB%8F%84%EC%A0%84",
"height": 256,
"width": 350,
"byteSize": 7438,
"thumbnailLink": "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSE-0T99jgFxHkru4hJWnv-JClGeLqfNZONbCxgNDK6M91tlJ-tobIH&s",
"thumbnailHeight": 88,
"thumbnailWidth": 120
}
},
{
"kind": "customsearch#result",
"title": "무한도전] ☆출구없는 매력☆ 고객 만족도 1위! 태국 전통쇼 계승자 ...",
"htmlTitle": "<b>무한도전</b>] ☆출구없는 매력☆ 고객 만족도 1위! 태국 전통쇼 계승자 ...",
"link": "https://i.ytimg.com/vi/9zcstq0pk74/hqdefault.jpg",
"displayLink": "www.youtube.com",
"snippet": "무한도전] ☆출구없는 매력☆ 고객 만족도 1위! 태국 전통쇼 계승자 ...",
"htmlSnippet": "<b>무한도전</b>] ☆출구없는 매력☆ 고객 만족도 1위! 태국 전통쇼 계승자 ...",
"mime": "image/jpeg",
"fileFormat": "image/jpeg",
"image": {
"contextLink": "https://www.youtube.com/watch?v=9zcstq0pk74",
"height": 360,
"width": 480,
"byteSize": 27547,
"thumbnailLink": "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRdW19HUY4FUO5X_FU9S2FEpM6bh0h3n6wJs3eQ9HOBRu1oBpuSUBz6S18&s",
"thumbnailHeight": 97,
"thumbnailWidth": 129
}
}
}
위 리턴값을 보자마자 내가 손수 selenium으로 크롤링해도 저거보단 데이터 적게 추출할거 같아서 크롤링을 하는 방식은 해당 API를 통해 진행해야겠다고 결론을 내렸다.
Google Custom Search API의 단점
지금까지는 API의 장점만을 이야기 하였는데 사실 단점도 존재한다. 가장 큰 단점은 API 파라미터에 특정 인덱스에서 부터 검색을 할수 있는 값이 존재하는데(startIndex) 약간 페이지 번호 같은 느낌이다. 위 결과값을 보면 totalResults 값이 158,000,000 인데, 이상하게 1부터 200까지의 값만 허용해주고 그 이외의 값은 403코드를 반환한다. 나는 하나의 키워드로 많은 데이터를 크롤링 하기를 원했는데, 원하는 바는 해당 API를 통해서 이루지는 못하게 되었다. 또 다른 단점으로는 무료버전에서의 키워드 검색 허용 일일 제한량은 100회이다. 그렇기에 1회 검색시에 10개의 게시글이 조회되고 , 하루에 대략적으로 1000개 정도의 게시글을 API로 정보를 리턴받을 수 있다.
서버 개발의 시작
크롤링 서버를 만들고자 하였으니, 크롤링 하는 방식이 정해지니 나머지는 일사천리도 진행되었다. 스프링부트 프로젝트를 생성하고 API를 각 정시마다 호출할수 있도록 Component를 Bean으로 등록하고 크롤링한 정보를 위 방명록 페이지 개발시에 연동했었던 FireBase RealTime DataBase에 저장할 수 있도록 구성하였다.
이미지 저장? 이미지 원본 URL 저장?
크롤링은 API를 호출하면 return 받는 값을 통해 이미지 원본 URL 값을 알 수 있었고 해당 URL을 통해 이미지를 다운로드 받을 수 있었다. 그런데 이미지를 다운받기 시작하면서 생각하지 못했던 부분이 있는데 이미지를 어디에 저장하지?에 대한 질문을 스스로 개발중에 하지 않았었고 크롤링에만 매몰되어 이 시점에서 이미지를 계속해서 다운을받아서 로컬에 저장할지, 혹은 외부 스토리지에 저장을 할지, 혹은 이미지 URL 링크값만 보관할지 고민이 되었다.
여러 방면으로 알아보던중 외부 스토리지를 사용하는 경우 FireBase의 Cloud Storage를 사용하거나, AWS의 S3를 사용하는 방법이 있는데 둘다 비용이 발생할 수 있는 서비스라서 선뜻 내 프로젝트에 적용하기에 꺼려졌다. 왜냐하면 최소한의 금액만을 가지고 개발하기를 원했고, 개발 초기부터 큰돈을 써가면서 개발하는게 큰 의미가 없다고 생각했기에 비용적인 부분을 생각하지 않을 수가 없었다. 또한 내가 사용자에게 적용하고자 하는 서비스는 이미지를 쉽게 복사/다운로드 할 수 있어야 하기에 외부 스토리지를 사용하는 경우 트래픽에 따른 비용이 어느정도 발생할지 짐작 조차 되지 않았기 때문에 더욱더 신중해 질 수 밖에 없었다.
결론적으로 위의 생각이 머리속에 가득차버리니, 어차피 큰 프로젝트 하는것도 아니고 사용자에게 이미지를 보여주고 복사/다운로드 기능을 제공하는것에 있어서 이미지 원본 URL 값만 알고 있어도 충분히 제공할 수 있을거라고 생각하였고, 만약 이 프로젝트가 차후에 커진다면 그때는 디비상에 존재하는 이미지 URL 값을 외부 스토리지에 이미지 자체를 저장하고 서비스를 제공하면 그만이라고 생각하여서 이 시점에서의 위의 질문의 답은 결국 이미지 URL 값을 DB에 저장하는 것으로 일단락 되었다.
EC2의 인스턴스 유형은 t2.micro
스프링 부트 서버를 구성한 것을 EC2에 배포하고자 하였다. 내가 잠을 자는 동안에도 알아서 서버가 동작하고 이미지를 가져오고 DB상에 저장을 해두어야 프론트에서 새로운 이미지를 계속해서 노출시킬 수 있을테니까 가장 먼저 하였던 작업이 EC2 인스턴스 생성 이었다. 최근에 AWS 강의를 들어서 EC2는 굉장히 빠르게 생성하였고 블로그에 기록해두었던 공부 내용이 빛을 내는 순간이 되었다. 그렇게 생성한 인스턴스에 GitHub에 저장한 소스를 Ubuntu 환경에 Git Pull을 진행하고 Build를 진행하였다.
Build는 생각보다 리소스를 크게 잡아먹는다.
일이 일사천리로 진행이 되고 있던 시점에서 이상한 현상을 목격하게 되었다. 스프링부트 프로젝트의 소스를 빌드하는 시점에서 자꾸 인스턴스가 멈춰버리는 현상이 발생하였다. 아예 먹통이 되어서 좀비마냥 반응이 없는 상태가 되어서 3-4번 정도 인스턴스를 삭제하고 재생성 하는 과정을 겪을 즈음에 갑자기 그런 생각이 들었다. 혹시 t2.micro의 인스턴스 유형의 스펙으로는 감당하지 못하는 작업인건가? 바로 구글에 검색을 진행 해보게 되었고 나와 같은 현상을 겪는 사람들이 굉장히 많다는 것을 알 수 있었다.
특히 https://rebugs.tistory.com/654 이분의 글을 통해 멈추는 이유와 해결방법에 대한 인사이트를 얻을 수 있었는데 t2.micro는 1개의 cpu와 1GB의 RAM을 제공하기에 스프링부트 프로젝트 Build시에 많은 메모리를 요구하게 되면서 Build가 실패하는 것으로 결과가 이어지게 되는 것이었다. 해결방법으로는 크게 두가지가 존재하였는데 첫번째는 인스턴스 유형을 업그레이드 하는것이다. 기존의 t2.micro 보다 더 좋은 사양으로 업그레이드 하면 빌드시에 필요한 메모리가 충족되면서 문제가 해결될수 있다. 두번째로는 swap을 사용하는 것인데, 시스템의 물리적 메모리(RAM)이 부족할 때 하드 디스크의 일부를 가상 메모리로 사용하는 것이다. 이렇게 하면 RAM이 부족할 때 시스템이 멈추는 대신 디스크를 사용하여 추가적인 메모리를 확보하여 작업을 완료 할 수 있다. 나는 첫번째 방법보다는 두번째 방법인 swap을 통해 문제를 해결하기를 원했고 EC2 Ubuntu 환경에 swap 설정을 하니, 빌드가 정상적으로 실행되는 것을 확인할 수 있었다.
SCP 방식의 CI/CD PipeLine 구축
스프링부트 코드도 잘 짯고, EC2에 빌드도 완료하여 구동도 완료하니, 자동화 과정이 필요하다고 생각했다. 즉 PipeLine에 대한 구축이 필요하다고 느겼다. 최근에 공부했던 SCP방식을 적용하고자 하였고, 프론트 소스는 어차피 깃허브 페이지에서 호스팅 되고 있었기에 구축이 필요없었고 백엔드 소스만 구축이 필요했다. 딱 이시점에서 1주일전에 공부하였었던 내용이었고 이렇게 빠르게 적용하게 될줄은 몰랐었는데 이때 작성하였었던 글의 내용을 참고하여 GitHub Actions로 PipeLine을 구축하였다.
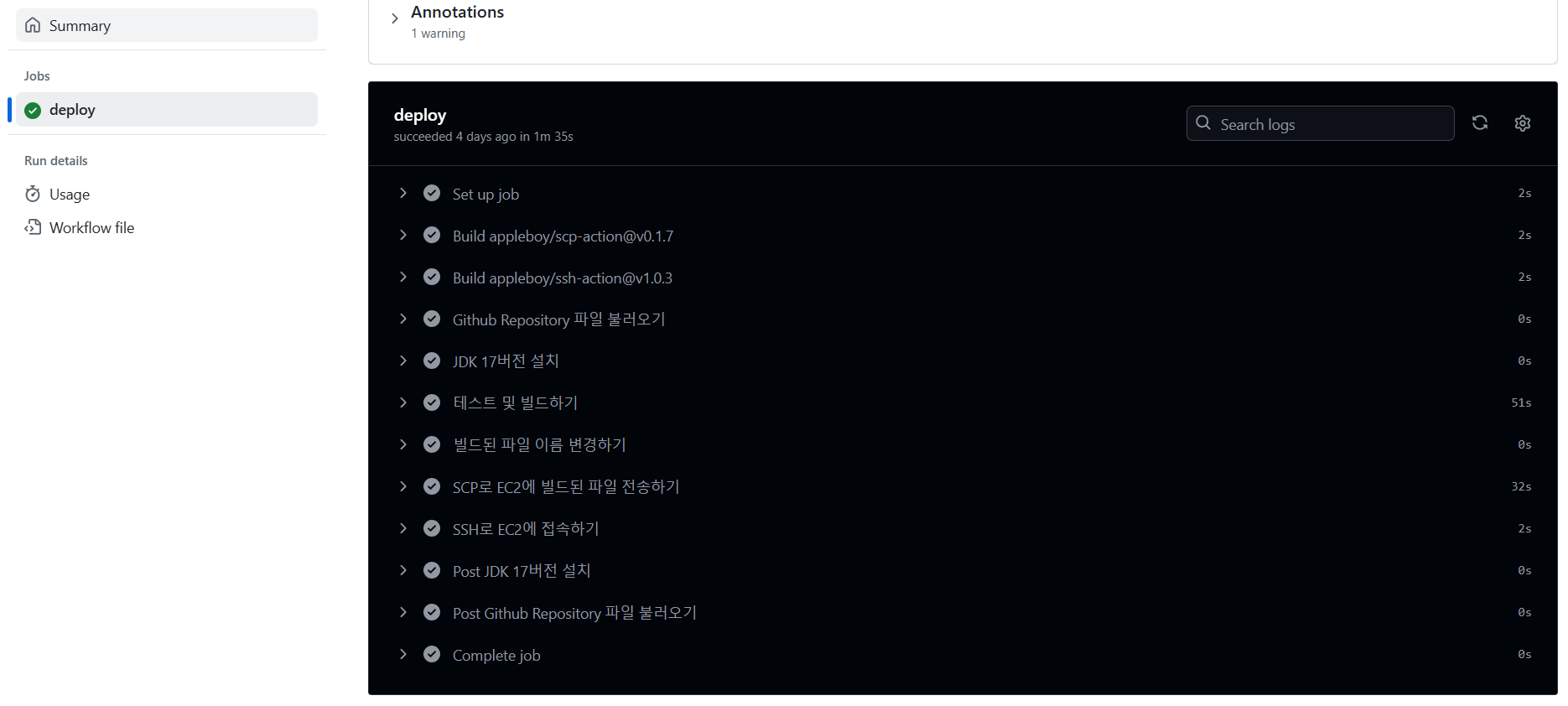
다음으로
프론트 소스는 깃허브 페이지에 호스팅하며, EC2에서 크롤링 서버가 돌아가며 데이터를 FireBase에 저장한다. 프론트는 FireBase에 저장된 데이터만 사용자 화면에 보여주는 간단한 구조를 가지고 있다. 다만 프론트 소스에서 FireBase DB에 직접 접근해야 하기에 js 파일에는 파이어베이스 키값이 하드코딩 되어 있어 보안적으로 위험 하였으며, 프론트가 DB에 직접 접근하는 이상한 구조가 마음에 들지 않았다. 또한 RDB가 아닌 FireBase를 사용하고 스프링부트에서 제어하려고 하니 굉장히 귀찮았다. 쿼리를 편하게 작성할 수 있는것도 아니고, 내가 기존에 하던 방식으로 데이터를 관리하는 것이 아니다보니, 시간이 지날수록 데이터가 많아짐에 따라 점점 버거워 지기 시작했다.
이러한 문제들을 해결하기 위해 보다 안전하고 효율적인 데이터 관리 방안을 모색하는 것이 필요하다고 느꼈다. Firebase의 편리함과 실시간 데이터 처리 능력은 매력적이지만, 보안과 확장성 측면에서 한계가 분명히 보였다(특히 섬세한 쿼리 조작이 불가하다). 앞으로는 RDBMS와 같은 전통적인 데이터베이스 시스템을 도입하고, 백엔드 서버를 통해 데이터 접근을 관리함으로써 보안성을 강화하고 데이터 관리의 효율성을 높이는 방안을 고려할 예정이다. 또한, 기존의 스프링부트 환경을 최대한 활용하여 개발 효율성을 유지하면서도 안정적인 서비스를 제공할 수 있는 구조를 구축하는 과정을 다음 글에 작성하고자 한다.
feat. 구입한 도메인을 EC2에 연결하고 무료로 https 적용하기